Qisqacha
- DeepSeek V4 bir necha hafta ichida chiqishi mumkin, elita darajasidagi kod yozish samaradorligiga yo'naltirilgan.
- Ichki manbalar uning Claude va ChatGPT ni uzun kontekstli kod vazifalarida ortda qoldirishi mumkinligini da'vo qilmoqda.
- Dasturchilar allaqachon ehtimoliy muammolar oldidan hayajonda.
Xabar qilinishicha, DeepSeek o'zining V4 modelini fevral oyi o'rtalarida chiqarishni rejalashtirmoqda va agar ichki testlar haqiqatdan dalolat bersa, Silikon vodiysidagi AI gigantlari xavotirga tushishi kerak.
Xanchjouda joylashgan AI startapi, tabiiyki, Oy Yangi Yili bilan mos ravishda, taxminan 17-fevral atrofida kod yozish vazifalari uchun maxsus ishlab chiqilgan modelni chiqarmoqchi, deb
. Loyihadan bevosita xabardor odamlarning ta'kidlashicha, V4 ichki testlarda ayniqsa juda uzun kod so'rovlarini qayta ishlashda, Anthropic’ning Claude va OpenAI’ning GPT seriyasidan o‘zib ketadi.
Albatta, model yoki uning ko‘rsatkichlari haqida hech qanday ma'lumot ommaga oshkor qilinmagan, shuning uchun bu da'volarni bevosita tekshirishning iloji yo‘q. DeepSeek ham bu mish-mishlarni tasdiqlamagan.
Shunga qaramay, dasturchilar hamjamiyati rasmiy xabarni kutmayapti. Reddit’dagi r/DeepSeek va r/LocalLLaMA allaqachon faollashgan, foydalanuvchilar API kreditlarini jamg‘arishmoqda, va X’dagi ixlosmandlar V4 DeepSeek’ni Silikon vodiysining milliard dollarlik qoidalariga bo‘ysunmaydigan jangchi sifatida mustahkamlashi mumkinligi haqidagi taxminlarini tezda baham ko‘rishmoqda.
Anthropic uchinchi tomon ilovalari, masalan OpenCode’da Claude obunalarini blokladi va xAI hamda OpenAI kirishini uzib qo‘ydi, deyilmoqda.
Claude va Claude Code zo‘r, lekin hali 10 barobar yaxshi emas. Bu boshqa laboratoriyalarni kodlash modellari/agentlari ustida tezroq ishlashga undaydi.
DeepSeek V4 chiqishi haqida mish-mishlar bor…
— Yuchen Jin (@Yuchenj_UW) 9 yanvar, 2026
Bu DeepSeek’ning birinchi marta bozorni izdan chiqarishi emas. Kompaniya 2025-yil yanvar oyida R1 reasoningi modelini chiqarganida, global bozorlarda 1 trillion dollarlik sotuvga sabab bo‘lgan.
Sababi nima edi? DeepSeek’ning R1 modeli OpenAI’ning o1 modeli bilan matematika va reasoningi testlarida tenglashgan, biroq atigi 6 million dollarga ishlab chiqilgani aytilgan edi, bu esa raqobatchilarning xarajatlaridan 68 barobar arzon. Uning V3 modeli keyinchalik MATH-500 testida 90.2% natijaga erishdi va Claude’ning 78.3% natijasini ortda qoldirdi, so‘nggi “V3.2 Speciale” yangilanishi esa unumdorlikni yanada yaxshiladi.
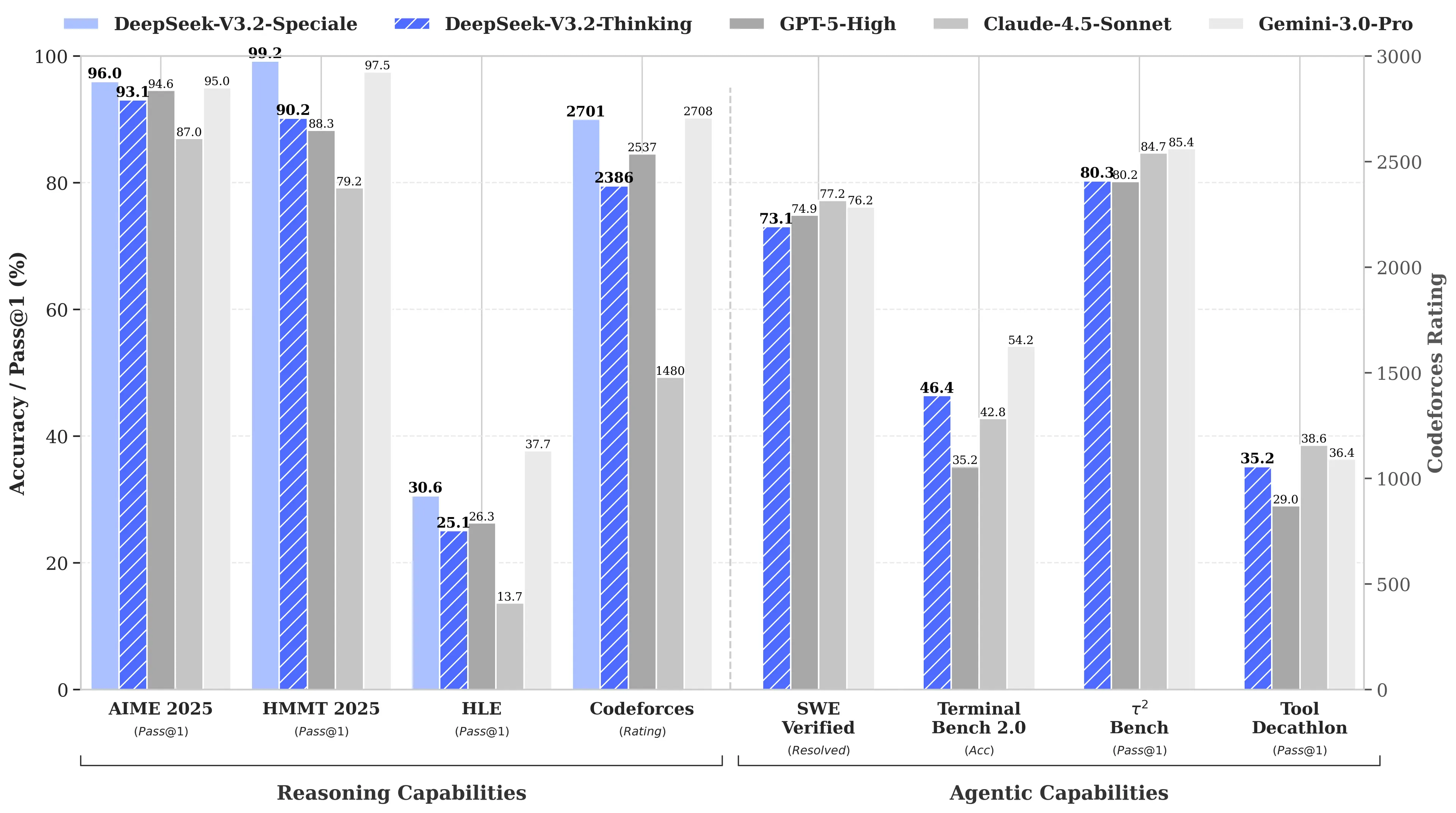
Image: DeepSeek
V4’ning kodlashga yo‘naltirilganligi strategik burilish bo‘ladi. R1 sof reasoning—mantiq, matematika, formal isbotlarga urg‘u bergan bo‘lsa, V4 aralash model (reasoning va no-reasoning vazifalar) bo‘lib, yuqori aniqlikdagi kod generatsiyasi bevosita daromadga aylanadigan korporativ dasturchilar bozorini nishonga oladi.
Ustunlikni qo‘lga kiritish uchun V4 hozirda SWE-bench Verified rekordini 80.9% bilan ushlab turgan Claude Opus 4.5 ni ortda qoldirishi kerak bo‘ladi. Ammo DeepSeek oldingi chiqishlariga qaralsa, Xitoy AI laboratoriyasi duch keladigan barcha cheklovlarga qaramay, bu imkonsiz bo‘lmasligi mumkin.
Unchalik maxfiy bo‘lmagan “sous”
Agar mish-mishlar to‘g‘ri bo‘lsa, bu kichik laboratoriya bunday yutuqqa qanday erishishi mumkin?
Kompaniyaning maxfiy quroli, ehtimol, 1-yanvar kuni chiqarilgan ilmiy maqolada: Manifold-Constrained Hyper-Connections yoki mHC da yashiringan. Asoschi Liang Wenfeng hammuallifligida yozilgan yangi o‘qitish usuli katta til modellari hajmini oshirishda asosiy muammoni hal qiladi — model barqarorligini yo‘qotmasdan yoki o‘qitish paytida “portlamasdan” qanday kengaytirish mumkinligini.
An’anaviy AI arxitekturasi barcha ma’lumotni bir tor yo‘lak orqali o‘tkazishga majbur qiladi. mHC esa ushbu yo‘lakni bir nechta oqimga kengaytiradi, ular o‘zaro ma’lumot almashishi mumkin, bu esa o‘qitish inqiroziga olib kelmaydi.
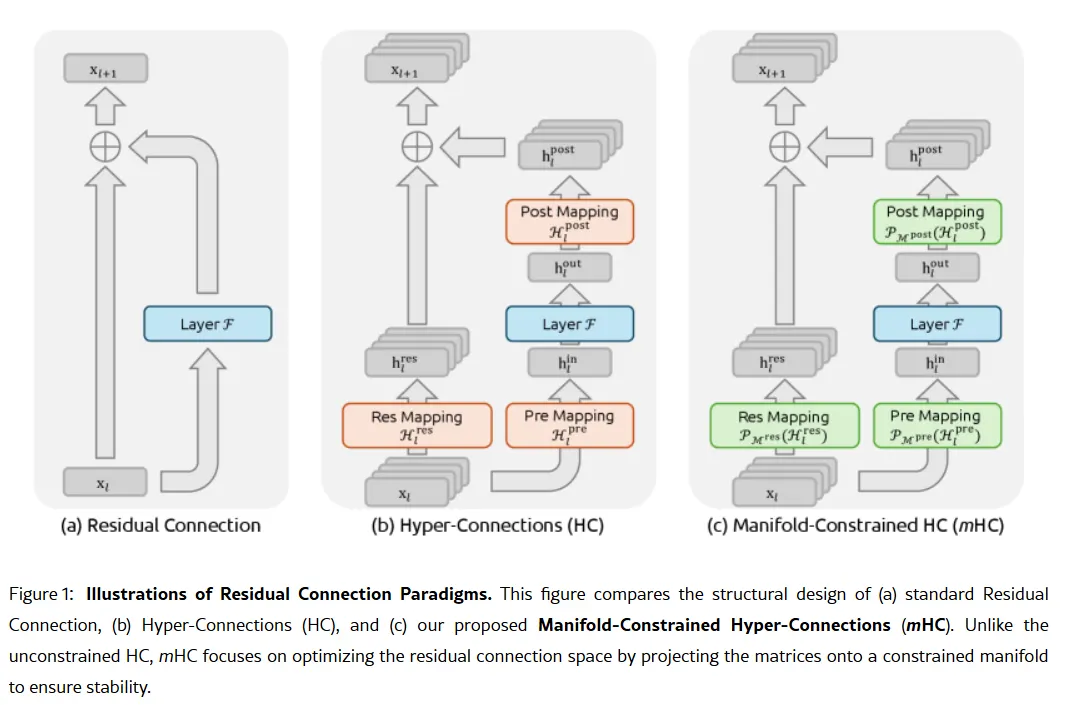
Image: DeepSeek
Counterpoint Research’da AI bo‘yicha bosh tahlilchi Wei Sun, mHC ni
. texnikasini “ajoyib yutuq” deb atadi. Unga ko‘ra, DeepSeek cheklangan ilg‘or chiplarga ega bo‘lsa ham, “hisoblash to‘siqlarini chetlab o‘tib, aqlning sakrashiga erishishi” mumkin.
Omdia’da bosh tahlilchi Lian Jye Su esa DeepSeek o‘z metodlarini oshkor qilgani “Xitoy AI sanoatida yangi ishonch paydo bo‘lganidan dalolat” deya ta’kidladi. Kompaniyaning ochiq kodli yondashuvi uni dasturchilar orasida mashhur qildi, ular DeepSeek’ni OpenAI’ning ilgari bo‘lgan holatiga o‘xshatishmoqda — yopiq modellar va milliard dollarlik investitsiyalarga o‘tishidan avvalgi davrga.
Hammaning ham ishonchi komil emas. Reddit’dagi ba’zi dasturchilar DeepSeek reasoning modellari oddiy vazifalarda hisoblash resurslarini behuda sarflaydi, deb shikoyat qilishmoqda, tanqidchilar esa kompaniya testlari haqiqiy hayotdagi murakkablikni aks ettirmasligini aytishmoqda. 2025-yil aprel oyida “DeepSeek Yomon — Va Men Endi Buni Inkorga O‘xshamayman” sarlavhali Medium posti viral bo‘lib, modellarni “xatolar bilan to‘ldirilgan, tayyor namunaviy kod” va “fantaziyadagi kutubxonalar” ishlab chiqarishda aybladi.
DeepSeek’ning boshqa muammolari ham bor. Maxfiylik masalalari kompaniyani ta’qib qilmoqda, ayrim hukumatlar DeepSeek’ning mahalliy ilovasini taqiqlagan. Kompaniyaning Xitoy bilan aloqalari va modellarida senzura bor-yo‘qligi haqidagi savollar texnik munozaralarga geosiyosiy tus berib yuboradi.
Shunga qaramay, rivojlanish sur’ati aniq. DeepSeek Osiyoda keng qo‘llanilgan va agar V4 kodlash bo‘yicha va’dalarini bajarsa, G‘arbda ham korporativ mijozlar uni qabul qilishi mumkin.
Image: Microsoft
Vaqt ham muhim.
xabariga ko‘ra, DeepSeek dastlab o‘zining R2 modelini 2025-yil may oyida chiqarishni rejalashtirgan, biroq asoschi Liang natijalardan norozi bo‘lgach, muddatni uzaytirgan. Endi, V4 fevralga, R2 esa ehtimol avgustga mo‘ljallangan, kompaniya tez harakat qilmoqda, bu esa yoki shoshilinchlikni yoki ishonchni, ehtimol ikkalasini ham anglatadi.


